



Pythonはデータ分析を得意としているプログラミング言語です。
Pythonを使ってデータ分析ができるようになれば、大量のデータを高速で処理できるようになり、エンジニアとしての価値も高まります。
そこで今回の記事では、Pythonのデータ分析について


という疑問を感じている方に向けて、Pythonを使ったデータ分析のやり方を紹介します。
データ分析に必要なライブラリや、データ分析の初歩的なやり方をメインに解説するので、これからPythonでデータ分析をやりたい方はぜひ参考にしてみてください!
記事のもくじ
Pythonのデータ分析の特徴とは?
まずはPythonのデータ分析にはどのような特徴があるのか、軽く触れておきましょう。
- 一連の分析はPythonで解決
- 自動で分析の操作ができる
- ほかの言語よりも汎用性がある
データ分析はExcelのVBAやR言語などでもできますが、Pythonのデータ分析には、ほかの分析方法よりも優れている点があります。
Pythonのデータ分析の特徴についてみていきましょう。
一連の分析はPythonで解決
そもそもデータ分析は、以下の流れで行われます。
- データの読み込み
- データの入力、加工、数値計算
- データのビジュアライズ(グラフなどの形にする)
- 機械学習のモデルの作成
以上の一連の流れが、Pythonだけで行えるようになっているのです。
データ分析の一連の流れがPythonで完結するのは、Pythonにさまざまなライブラリが用意されているため。
一つのライブラリで実行できることは限られているものの、複数のライブラリを駆使すればデータ分析を一通り行えるようになっています。
Pythonでデータ分析が完結できると考えると、Pythonは学習のコスパが高い言語といえるでしょう。
自動で分析の操作ができる
Pythonを使えばデータの抽出、削除、統合などの分析に必要な操作を自動化できます。
ExcelのVBAもデータ分析で使われることがありますが、手動で処理をする場面が多いため、データを処理する機会が多いと必然的に時間を取られてしまうでしょう。
しかしPythonは、データ分析の操作を自動化してくれるおかげで、分析にかかるコストを大幅に抑えられます。
またPythonは大量なデータを素早く処理することにも長けているため、データ分析を大幅に効率化できること間違いないでしょう。
ほかの言語よりも汎用性がある
ほかの言語と比べて汎用性があるという点も、Pythonならではのメリットです。
Python以外にデータ分析で使えるプログラミング言語として、R言語があげられます。
R言語はデータ分析に必要な機能が豊富に揃っており、データサイエンティストなどの専門家が使用することの多い言語です。
しかし「汎用性」の点では、R言語よりもPythonの方が優っています。
R言語はデータ分析で使用されることがメインですが、Pythonはデータ分析のみならず「機械学習」「Webサービス(アプリ)の開発」などにも使用できます。
データ分析を専門的に学びたいのであればR言語がおすすめですが「機械学習やWebサービスの開発などもやってみたい」という方はPythonがおすすめです。
- 「データ分析を専門的に学びたい」 →R言語
- 「機械学習やWebサービスの開発などもやってみたい」 →Python
Pythonのデータ分析で使用するライブラリ

Pythonを使ってデータ分析をする場合、Pythonをインストールするだけではまだ必要なものが足りません。
Pythonでのデータ分析をする場合、以下のライブラリをインストールしましょう。
- Pandas
- Numpy
- matplotlib
- scikit-learn
ライブラリとは、Pythonに機能を追加してくれるプログラムのことです。
ライブラリをインストールすれば、Pythonで便利にデータ分析できるようになりますよ。
データの処理ができるPandas
Pandasとはデータの処理に特化したライブラリで、さまざまなファイル形式のデータを扱えるのがメリット。
データ分析では列と行がある表形式のデータを扱うことがありますが、Pandasは「csv」「excel」「SQLデータベース」などの表形式のデータは一通り扱えます。
Pandasは表形式のデータに対し、以下のような操作ができます。
- データの新規作成
- 特定のデータの絞り込み
- 複数のデータの結合
- データの削除
- 平均値や標準偏差の算出
Pandasでのデータ操作には関数を用いることがありますが、Pandasの関数はSQLで使う関数と類似しています。
そのためSQLの学習をしている方であれば、スムーズにPandasを利用できるようになるでしょう。
数値計算ができるNumPy
NumPyとは数値計算を高速で行えるライブラリです。
NumPyをインストールせずともPythonで数値計算はできるものの、C言語やJavaを使った数値計算に比べると、スピードはかなり劣ります。
しかしNumPyの内部はC及びFortranが用いられているため、NumPyをインストールすれば、従来のPythonよりも数値計算が格段に早くなります。
またNumPyではnp.ndarray という独自の機能を用いて計算が可能です。
np.ndarrayとは多次元配列を扱える機能で、1次元や2次元などの配列を扱えます。
np.ndarrayを使えば短めのコードで計算できますし、コードが短い分計算処理のスピードも早くなります。
グラフを作成できるmatplotlib
matplotlibとはPythonでグラフを作成するためのライブラリです。
matplotlibはNumPyと一緒に使われることが多く、折れ線グラフや円グラフ、3Dグラフなどのグラフを描けます。
データ分析の際にデータをグラフとして描写すれば、データの変移の特徴をつかみやすくなるでしょう。
グラフの線や点の色、太さも自由自在に変更できるので、デザイン性にも優れています。
機械学習で使うscikit-learn
scikit-learnは、機械学習で使われるライブラリです。
機械学習は以下の流れで行われます。
- データの用意
- モデル(機械学習の手法)の選択
- 学習
この機械学習の一連の流れは、scikit-learnを使えば効率よく進められます。
機械学習にはさまざまなモデル(手法)があり「回帰」「ニューラルネットワーク」「クラスタリング」「アソシエーション分析」などがありますが、scikit-learnは機械学習のモデルを豊富に用意しています。
「機械学習ってコードを書くのが難しそう…」というイメージがありますが、scikit-learnを使えばシンプルなコードで機械学習を実装できるので、機械学習の初学者でも安心して使えますよ。
4つのライブラリのインストール方法
「Pandas」「NumPy」「matplotlib」「scikit-learn」の4つのライブラリは、簡単にインストールできます。
いずれのライブラリでも、インストールの際はコマンドプロンプト(Macの場合はターミナル)を使用します。
コマンドプロンプト(ターミナル)に以下のコマンドを入力します。
$ pip install numpy
$ pip install numpy
$ pip install matplotlib
$ pip install scikit-learn
これでPythonの4つのライブラリを使えるようになります。
Pythonのライブラリの基本的な使用方法

「Pandas」「NumPy」「matplotlib」「scikit-learn」の基本的な使い方を紹介します。
基本的な使い方を覚えて、これからデータ分析の学習を本格的に進めていきましょう!
Pandas
まずはPythonにPandasをimportしましょう。
import pandas as pd
データの読み込み・作成
CSVなどの外部ファイルを読み込む場合は、以下のコードで読み込みます。
#CSVの読み込み
df_csv=pd.read_csv(‘csvファイルのパス’)
#テキストファイルの読み込み
df_txt=pd.read_table(‘テキストファイルのパス’)
#TSVの読み込み
df_tsv=pd.read_csv(‘tsvファイルのパス’, delimiter=’\t’)
データを作成する場合、1次元のデータを作りたいときはSeries()、2次元のデータを作りたいときはDataFrame()を使います。
#1次元データの作成
s=pd.Series([1,2,3,4,5])
print(s)
#2次元データの作成
df=pd.DataFrame({‘α’:[‘a’,’b’],’β’:[‘c’,’d’],’γ’:[‘e’,’f’]})
print(df)
すると以下のように出力されます。
0 1
1 2
2 3
3 4
4 5
dtype: int64
α β γ
0 a c e
1 b d f
1次元データの作成で縦の項目にラベルを指定しない場合、自動的にラベルが付与されます。
データの削除
特定のデータを削除したい場合は、drop()を使いましょう。
第一引数に列(行)のインデックスを指定し、列を削除する場合はaxis=0、行を削除する場合はaxis=1を第二引数で指定します。
# 2次元データの作成
df=pd.DataFrame({‘α’:[‘a’,’b’],’β’:[‘c’,’d’],’γ’:[‘e’,’f’]})
# 列を削除する
df=df.drop(0,axis=0)
print(df)
出力結果は以下のとおりです。
α β γ
1 b d f
0の列が削除されました。
NumPy
まずはPythonでNumPyをimportしましょう。
import numpy as np
配列の作成
NumPyではarrayを使って配列を作成します。
多次元の配列を作ってみましょう。
arr=np.array([[1,4,9],[16,25,36]])
print(arr)
出力結果は以下のとおりです。
[[ 1 4 9]
[16 25 36]]
配列の計算
NumPyでは、配列の値を四則演算で変更することができます。
arr=np.array([[1,4,9],[16,25,36]])
arr=arr*10
print(arr)
arrに10をかけたら、arrの配列の値は10倍になります。
[[ 10 40 90]
[160 250 360]]
また、配列同士で計算することもできます。
arr=np.array([[1,4,9],[16,25,36]])
arr2=np.array([[1,2,3],[5,7,11]])
arr3=arr+arr2
print(arr3)
arrとarr2を足すと、配列にあるそれぞれの値がプラスされます。
[[ 2 6 12]
[21 32 47]]
配列に新たな要素を追加
appendを使えば配列に新たな要素を追加できます。
arr=np.array([[1,4,9],[16,25,36]])
arr2=np.append(arr,[[49,64,81]])
print(arr2)
二次元配列の場合、一次元に平坦化されてしまいます。
[ 1 4 9 16 25 36 49 64 81]
しかし第三引数でaxisを使い、0を指定すると縦方向に、1を指定すると横方向に追加されていきます。
axisを使えば次元を保てます。
arr=np.array([[1,4,9],[16,25,36]])
arr2=np.append(arr,[[49,64,81]],axis=0)
print(arr2)
[[ 1 4 9]
[16 25 36]
[49 64 81]]
arr=np.array([[1,4,9],[16,25,36]])
arr2=np.append(arr,[[49,64,81],[100,121,144]],axis=1)
print(arr2)
[[ 1 4 9 49 64 81]
[ 16 25 36 100 121 144]]
matplotlib
まずはmatplotliのpyplotをimportします。
import matplotlib.pyplot as plt
線グラフの作成
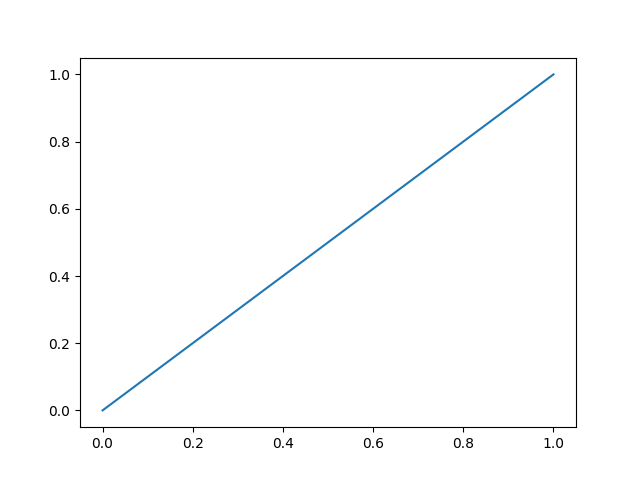
一次関数の線グラフを作ってみましょう。
x = np.linspace(0,1,100)
y = x
plt.plot(x, y)
plt.show()
すると以下のような直線グラフができあがります。
円グラフの作成
円グラフを作成する場合、plt.pieを使います。
labelsを引数に使うと、要素に対して名前をつけられます。
x = np.array([5,20,17,36,22])
label = [“A”,”B”,”C”,”D”,”E”]
plt.pie(x,labels=label)
plt.show()
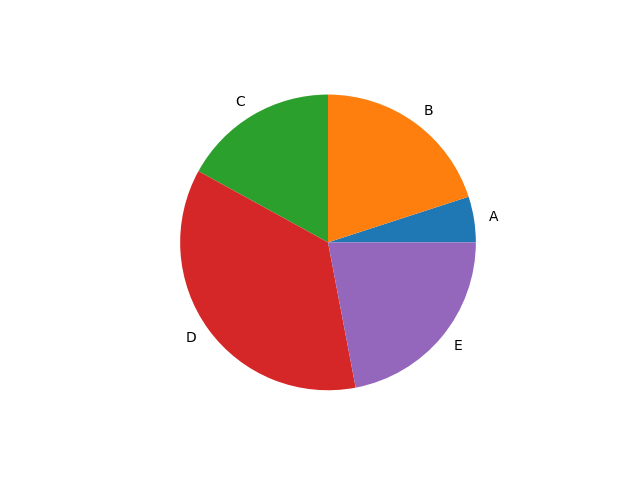
ただこれだとデータの順番が反時計回りですし、1番目のデータであるAが0時の方向にありませんよね。
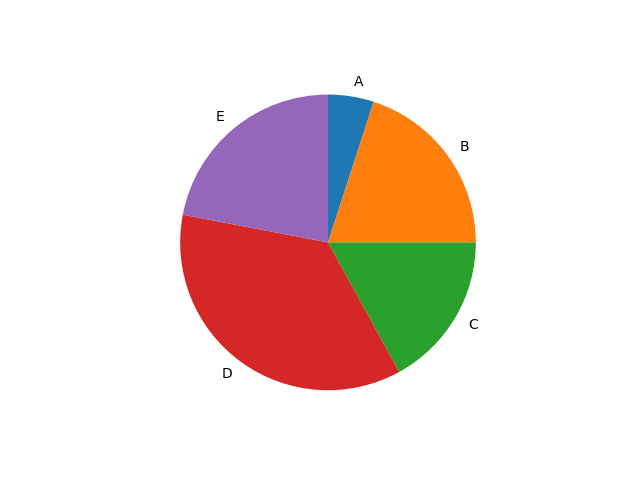
データの順番を時計回りにして、1番目のデータの位置を0時の方向に置く場合、以下のコードを書きましょう。
x = np.array([5,20,17,36,22])
label = [“A”,”B”,”C”,”D”,”E”]
plt.pie(x,labels=label,counterclock=False,startangle=90)
plt.show()
scikit-learn
scikit-learnは基本的に、scikit-learnの一部のモジュールだけをimportするのが主流です。
今回はSVMで機械学習をやってみましょう。
from sklearn import datasets, svm
以下のようなコンビニの売上データを使ってみます。

もし気温が20度だったとき、どの商品が一番売れるのかを機械学習で予測してみます。
# 気温のデータ
temp=[[10],[24],[28],[8],[17],[31],[25]]
# 商品のデータ
prod=[0,1,2,0,3,2,1]
# 学習させる
clf=svm.SVC()
clf.fit(temp,prod)
# 20度の場合に売れる商品を予測
test_temp=[[20]]
test_prod=clf.predict(test_temp)
# 結果を出力
print(test_prod)
結果は以下のとおりです。
[1]
気温が20度のときは、バニラアイス(1)が売れると予測できました。
Pythonでデータ分析をする方法|ライブラリの使い方も解説のまとめ

Pythonのデータ分析の特徴や、ライブラリの基本的な使い方を解説しました。
今回紹介したライブラリの使い方は、あくまで基本的なものですので、本格的にデータ分析するにはより学習が必要です。
ですが基本的な使い方はあまり難しくはないので、どなたでも無理なく学習をスタートできるでしょう。
今回紹介したことをきっかけに、Pythonを使ったデータ分析の手法を身につけていきましょう!
英語でプログラミングを学べるKredo
英語×プログラミングのスキルを身につけてグローバルに活躍しませんか?
当メディアを運営しているKredoは、英語×プログラミングをオンラインで学ぶ「Kredoオンラインキャンプ」と、フィリピンのセブ島で学ぶ「KredoIT留学」を提供しています。これまでの卒業生は2,000名を超え、卒業生の多くが、国内外のIT企業への転職、フリーランスなどへのキャリアチェンジを実現しています。これからの時代に必要な英語×プログラミングのスキルを身につけてグローバルに活躍しませんか?









