





このような疑問、要望を持つあなたに向けた記事です。
AIがどのような学習方法を用いるのか、どのようなアルゴリズムが使われているのかを知りたい方向けの記事となっています。
具体的には、次の順番でお話ししていきます。
- 機械学習とディープラーニングの違い
- 機械学習のアルゴリズム
- 機械学習の種類
- ディープラーニングのアルゴリズム
AIの学習方法の概要を知りたい方は、ぜひ一読ください。
Kredoオンラインキャンプでは、フィリピン人講師から毎日リアルタイムレッスンで「英語×プログラミング」を学べます。
「英語×プログラミング」を学ぶのは難しそうと感じるかもしれませんが、基礎から学べるカリキュラムとなっているので、初心者でも安心です。
新たな挑戦をしたいと思ったら、ぜひ無料カウンセリングへお越しください。

記事のもくじ
AI(人工知能)プログラミングの学習方法が知りたい人はこちらを確認
 この記事は、AIが学習する方法について記載した記事です。
この記事は、AIが学習する方法について記載した記事です。
AIプログラミングの学習方法が知りたい方は、次の記事を参照ください。



AIが学習する方法の違い|機械学習とディープラーニング
 AIの学習方法を知る上で、最近よく聞く「機械学習」と「ディープラーニング」の違いは理解しておかなければなりません。
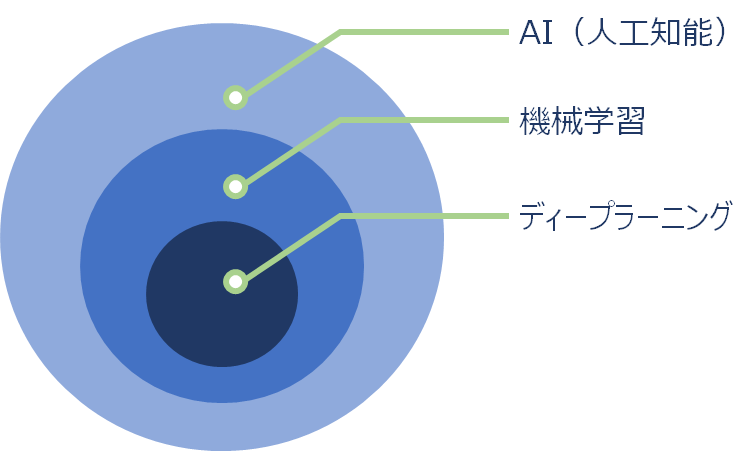
AIの学習方法を知る上で、最近よく聞く「機械学習」と「ディープラーニング」の違いは理解しておかなければなりません。
AIの学習する方法として機械学習があり、機械学習の中にディープラーニングという学習手法があります。
機械学習は、AIの学習方法の一つであり、次の学習方針を持ちます。
- 特徴を掴んで法則化する
- 法則を自動化する
機械学習は、トレーニングによって特定のタスクを実行できるようにするための学習方法です。
ディープラーニングは、深層学習とも呼ばれる機械学習の一種です。
機械学習では、判定基準を人間が与えることによって、与えられた基準を元に学習を行います。
ディープラーニングでは、自ら判定基準を学習し、自動でどんどん学習を行うものです。
AIの学習方法①:機械学習のアルゴリズム
 機械学習のアルゴリズムは数多く存在しており、その中でも、大きく分類は5つに分けることができます。
機械学習のアルゴリズムは数多く存在しており、その中でも、大きく分類は5つに分けることができます。
機械学習のアルゴリズムを理解するためのチートシートとして有名な「scikit-learn cheat-sheet」を元に解説していきます。
scikit-learn cheat-sheetと合わせて、Microsoftの「Azure Machine Learning Studioの機械学習アルゴリズムチートシート」も参考になりますので、参照してみてください。
Classification(分類)
分類は「2クラス分類」と「マルチ分類」に分けられます。
2クラス分類は、ラベル付きデータを学習して、2値に分類する手法です。
マルチ分類は、ラベル付きデータを学習して、3値以上に分類する手法となります。
たとえば、果物の名前を分類することはマルチ分類、スイカが果物か野菜か(正常/異常)を分類することは2クラス分類です。
- ロジスティック回帰
- デシジョンジャングル
- ブースト決定木
- ニューラルネットワーク
- 平均化パーセプトロン
など
- ロジスティック回帰
- ニューラルネットワーク
- 一対全多クラス
- K近傍法
など
Regression(回帰)
回帰は、数値データを学習して、数値を予測する手法です。
正しい数値と入力データの組み合わせを学習することで、データのパターンを学習し、未知のデータから数値を予測します。
たとえば、株価の予測や競馬の予測など、これまでの数値データを元に関連性を見出して、未知の数値を予測します。
- 線形回帰
- ベイズ線形回帰
- サポートベクトル序数回帰
- ポアソン回帰
- ラッソ回帰
など
Clustering(クラスタリング)
クラスタリングは、似ているデータを集めて、データ構造を発見する手法です。
与えられたデータを複数に分類します。
さまざまなデータを分類することから、「分類」の手法と似ていますが、学習方法に違いがあります。
分類は「教師あり学習」であるのに対し、クラスタリングは「教師なし学習」です。
教師あり学習と教師なし学習の違いについては、後述します。
- k平均法
- 混合ガウス分布
- スペクトラルクラスタリング
Dimension reduction(次元削減)
次元削減は、データの次元を削減し、主要因子を発見する手法です。
学習をする際には、データの特性を表す指標を多く使用します。
指標が多い場合、データの数が増えるにつれてデータの特性が掴みづらくなってしまいます。
そこで、あまり差の出ない情報を捨て、解釈しやすい次元まで指標をまとめることが次元削減です。
たとえば、国語・数学・理科・社会という指標があり、それぞれの点数が80・45・50・70の人がいたとします。
この4つの指標(4次元)を文系・理系という2つの指標(2次元)に減らすと、理系平均が47.5点、文系平均が75点となります。
次元を減らしたことで、データからこの人は「文系が得意な人」という特性が導き出せました。
このように、データの可視化のために次元削減はもちいられます。
データの可視化のほかにも、データの圧縮のためにもちいられる場合もあります。
- 主成分分析
- 非負値行列因子分析
- LDA
- ディープラーニング
Anomaly detection(異常検知)
異常検知は、データの標準を学習させ、標準から乖離したデータを異常として処理させる手法です。
「分類」「回帰」「クラスタリング」「次元削減」と同列になっていますが、これらとは異なり、応用のカテゴリーに属します。
異常検知の範疇には、現在の「異常検知」と未来の「予知保全」があります。
たとえば、現在の異常検知は、建築物のひび割れなどの異常を検知するものです
未来の予知保全は、音や振動などから将来的に異常となり得る予兆を検知するものとなります。
- サポートベクターマシン
- PCAによる異常検知
- k平均法
AIの学習方法②:機械学習の種類
 機械学習は3つの種類に分類されます。
機械学習は3つの種類に分類されます。
それぞれの学習の種類は、どのようなものであるのか、利用されるアルゴリズムと合わせて解説していきます。
教師あり学習
教師あり学習は「入力と出力の関係」を学習するものです。
「分類」「回帰」の手法は、教師あり学習に分類されます。
正解となるデータを学習させることで、出力結果として分類や予測をすることが可能となります。
たとえば、迷惑メールフィルタや株価の予測が代表的な例です。
迷惑メールフィルタは、メールの文章を入力することで、出力として迷惑メールであるか否かを分類します。
株価の予測は、株式データを入力することで、未知の株価を予測しています。
教師となる「入力データ」と「正解データ」を与える学習の種類が、教師あり学習です。
教師なし学習
教師なし学習は「データの構造」を学習するものです。
「クラスタリング」「次元削減」の手法は、教師なし学習に分類されます。
教師あり学習とは異なり、正解データを与えられずに学習することが特徴です。
コンピュータ自身が似ているデータをグループに分けたり、頻出パターンを見つけ出します。
たとえば、スーパーの購買情報を元に、ユーザーを年齢別のグループに分けることができます。
ほかにも「おむつとビールは一緒に購入されることが多い」といった、一見すると関係がなさそうな頻出パターンを見つけ出す事が可能です。
「おむつとビール」の話は、データマイニングの有名な話であり、このようなグループ分けや、頻出パターンを見つけ出す手法は、ビッグデータでの分析に利用されています。
強化学習
強化学習は「試行錯誤を通じて、価値を最大化するような行動」を学習するものです。
教師あり学習と似たアプローチを行いますが、与えられた正解データをそのまま学習するのではなく、正解データの「価値」を最大化する行動を学習します。
チェスや囲碁などのゲームを学習させることに適した学習の種類です。
コンピュータ自身が試行錯誤を繰り返した経験から、最も適した行動を学んでいく学習の種類が強化学習となります。
AIの学習方法③:ディープラーニングのアルゴリズム
 ディープラーニングのアルゴリズムも多数存在しています。
ディープラーニングのアルゴリズムも多数存在しています。
その中でも利用頻度が高く、覚えておきたい3つのアルゴリズムを紹介します。
CNN(畳み込みニューラルネットワーク)
CNNはConvolutional Neural Networkの略です。
ディープラーニングのアルゴリズムの中で、ほとんどの画像認識や動体検知に使われるものがCNNとなります。
「畳み込み」とは、端的に言ってしまえば「画像の特徴を際立たせること」です。
CNNでは、画像全体をそのまま覚えるのではなく、画像の特徴を抽出して覚えます。
CNNは「畳み込み層」と「プーリング層」でできています。
畳み込み層で抽出した特徴を元に特徴マップを作成し、プーリング層で特徴マップの要約を行います。
プーリングを行うことにより、画像内での特徴を正確に検出することが可能となります。
このことから、画像認識や動体検知の分野で使用されることが多いディープラーニングのアルゴリズムとなっています。
RNN(再帰型ニューラルネットワーク)
RNNは、Recurrent Neural Networkの略です。
自然言語処理の分野で利用されることが多く、機械翻訳や文章生成、音声認識に利用されています。
従来のニューラルネットワークは、言語のように連続性がある入力値の処理を苦手としていました。
RNNでは、入力層・中間層・出力層の3層構造の中にある、中間層にループを組み込むことで、前の入力を記憶できるようにしています。
そのことにより、前後の文脈から言葉の意味を理解できるようになりました。
LSTM(長・短期記憶)
LSTMは、Long Short-Term Memoryの略です。
RNNの問題を解決するために考案されました。
RNNの問題とは、文章や動画などで長い時系列のデータを処理しようとすると、演算量が爆発的に増加し、処理不能となる問題です。
LSTMでは、情報を忘れる機能が追加されており、情報を必要・不必要と判断できるようになりました。
LSTMでは、長い時系列のデータも処理できるようになったため、機械翻訳の精度の向上に大きく貢献しています。
まとめ:AIの学習方法は多岐にわたる
 AIの学習方法として、機械学習やディープラーニングが非常に注目されています。
AIの学習方法として、機械学習やディープラーニングが非常に注目されています。
機械学習の種類でも、教師あり学習や教師なし学習、強化学習と分かれており、さまざまなアルゴリズムを駆使しています。
ここで紹介した内容は、AIの学習方法の一部です。
AIを構築するためには、知識の広さと深さが必要であることが垣間見えますね。
AIの学習方法を、いきなり全て身につけることは難しいものです。
あなたが目的とするAIの処理を実現させるために、一つずつ着実に学んでいきましょう。
英語でプログラミングを学べるKredo
英語×プログラミングのスキルを身につけてグローバルに活躍しませんか?
当メディアを運営しているKredoは、英語×プログラミングをオンラインで学ぶ「Kredoオンラインキャンプ」と、フィリピンのセブ島で学ぶ「KredoIT留学」を提供しています。これまでの卒業生は2,000名を超え、卒業生の多くが、国内外のIT企業への転職、フリーランスなどへのキャリアチェンジを実現しています。これからの時代に必要な英語×プログラミングのスキルを身につけてグローバルに活躍しませんか?









